
Being upfront: all these experiments were done by my coworker Jacob Fancher (GitHub), I’m just writing it up because I think it’s cool :)
At Roam, we have an AI assistant called “On-It!” that, among other things, can open a chat between two users, with itself in the middle to close out any tasks discussed:
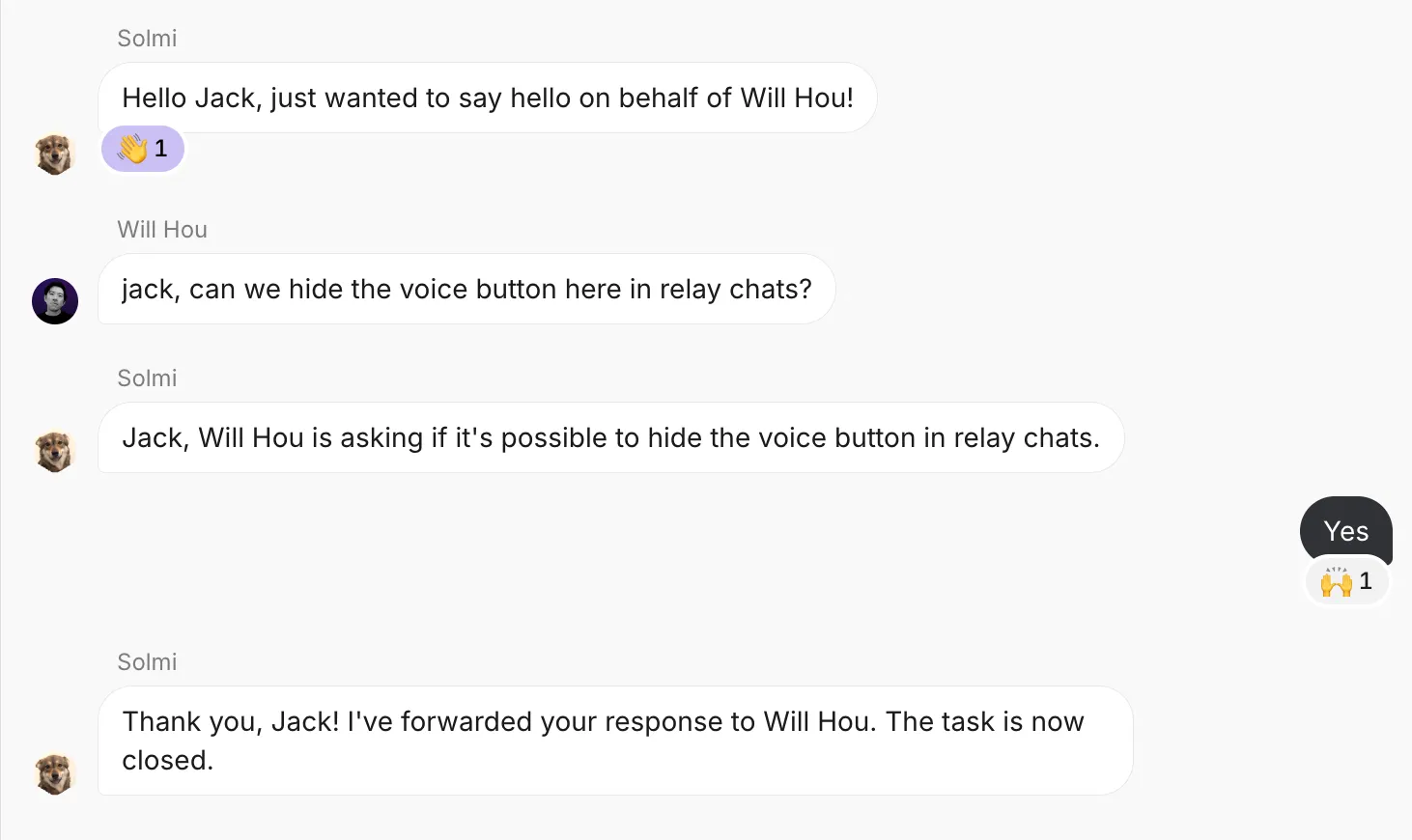
Unfortunately, this can lead to some pretty stilted conversations; the AI butts in after every message as if it were addressed to it directly, even when the users are pretty clearly just talking to each other. The above example is mostly fine, but for longer conversations it gets really annoying. Turns out, our code had no way for an AI to refuse to answer a message, so we set out to fix that.
Things That Don’t Work
- Sentinel string: Telling the AI, to effect, “if you think you shouldn’t respond, reply ‘No comment’”, or other such strings. The AI’s response would be compared against the sentinel, and the message not sent if it matched.
- Optional tool call: Telling the AI, “If you think you shouldn’t respond, use this
dont_respondtool call instead of sending a message.” The AI already knew about a bunch of other tool calls (for scheduling meetings, creating new tasks, etc.), so if we saw it make this one, we would not send the message. - Enforced tool call: Making it so there are both
respond&dont_respondtool calls, and only by using therespondtool call can the AI send messages back to the user.
Unfortunately, none of these approaches worked! No matter what, the AI would do whatever it could to send a message back to a user, even entirely useless ones as before.
Hypothesis For Why
Our AI is built on top of OpenAI’s ChatGPT API, which is LLM-based2. Modern LLMs innately expect to complete a message by responding to it, and get very angsty when they can’t respond. This is because the process for turning a “base” model (just trained on raw text) into something like ChatGPT involves a lot of fine-tuning on chat-specific data, enforcing “roles” like user (for messages input by the user) and assistant (for responses created by the AI). OpenAI’s API even encodes these roles directly so you don’t have to manually format the input, it’s all done under the hood for you.
So, the fine-tuning makes an LLM always want to put an assistant message after every user message, no matter what. No amount of prompt engineering can counteract an LLM’s innate drive to respond to a user; even the “Enforced Tool Call” approach is treated as merely a fancy response format. In order get the AI to not respond, we need a different prompting strategy entirely.
The Thing That Does Work
We landed on a 2-step approach: first, we have an “evaluator” prompt with instructions to decide whether or not the AI should respond, outputting into a structured JSON object containing just a boolean should_respond field. Then, we have the normal “responder” prompt that does the rest of the work, crafting a response & making tool calls. Separating out the prompts like this frees each part to think about only what it needs to; the “evaluator” is happy saying true/false as a complete response, and the “responder” only has to think about what it should respond with, which usually overpowers any thought as to if it should respond.
Unfortunately, doing it in two stages like this is a wee bit more expensive, and requires a non-trivial change to our backend, so we decided not to go through with it for now. Still, good to know what we should do whenever this comes up again!
Footnotes
-
Solmi, Will’s dog, is also featured in another post of mine talking about a Chrome rendering bug (now fixed). Thank you for helping us debug our software, Solmi <3 ↩
-
Really, what AI isn’t LLM-based nowadays… ↩